Backprop is a dynamic programming hack to store the local derivatives for each neuron in the forward pass, and use them during the backward prop. This way we only calculate the local gradients only once as compared to calculating the same gradients for all different combinations of weights. We also express the gradient of weights of a particular layer in terms of gradients of previous layers(moving backwards). This helps us to reuse the pre-computed local gradients.
Local gradients for a neuron is the derivative of it’s output wrt each of it’s input(weights, biases, previous layer ouput).
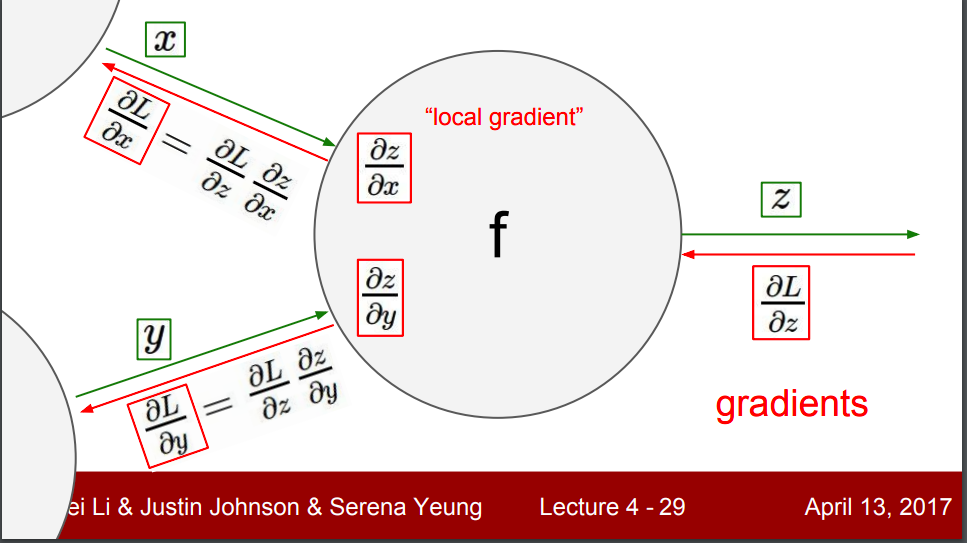
Note: for a neuron, it involoves 2 steps - calculatuing the matmul, and passing the matmul through an activation function. For a neuron with activation function f,
For our particular case,
We have one hidden layer with output z1, weight w1, with relu activation(f1). And output layer with output z2, weight w2, and softmax activation(f2).
We use cross entropy loss(J) =
Now, to minimize the loss, we have to calculate the gradient of loss function wrt weights of the network, and update the weights accordingly(gradient descent). So we need to calculate -
First look at the case for gradient wrt W2. Here, by chain rule, we first calculate the gradient wrt to the output of layer 2, and then gradient of output wrt W2 (local gradient)
So the above equation can be written as -
Now, when the loss function is cross entropy and the activation function is softmax, the above equation becomes -
For calculating the gradient of loss wrt W1:
We want to see how a change in W1 affects the loss. W1 affects Z1 which affects Z2 which affects the loss. Or we can backtrack the path from loss to W1.
Substituting the local gradient for layer 1 -
Substituting the local gradient for layer 2 -
So the derivative equation becomes -
As computed for first gradient, this equation finally becomes -
Additional Note:
Derivative of softmax -
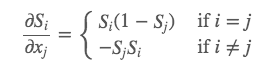
Derivative of sigmoid -
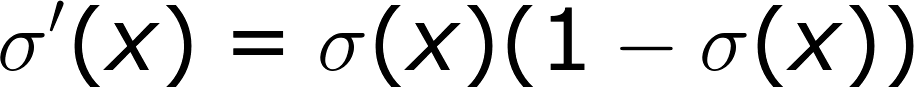
For binary cross entropy with sigmoid activation, the derivative is -