One of the biggest challenge for deep learning is getting appropriate supervisions for the task. The scope of applications of deep learning/computer vision has also increased significantly. The tasks evolved from predicting the category of the objects in the image to predicitng the 3d models of the object, and other physical properties of the objects. Gathering supervision for such tasks is impractical.
Well, a new area of research called learning via prediction consistency solves for this problem. By providing appropriate priors for the desired output(not per instance level) and enforcing a consistency loss i.e. the predicted output from the model should match with the input, we are able to use the self supervision to learn the intermediary state.
The priors is the information we have about the world model. It can be a 3d model or a physics simulator. We also need to a differentiable mechanism to convert from intermediate state to back to the input state. Eg - 3d to 2d, or physics simulator to the next video frame.
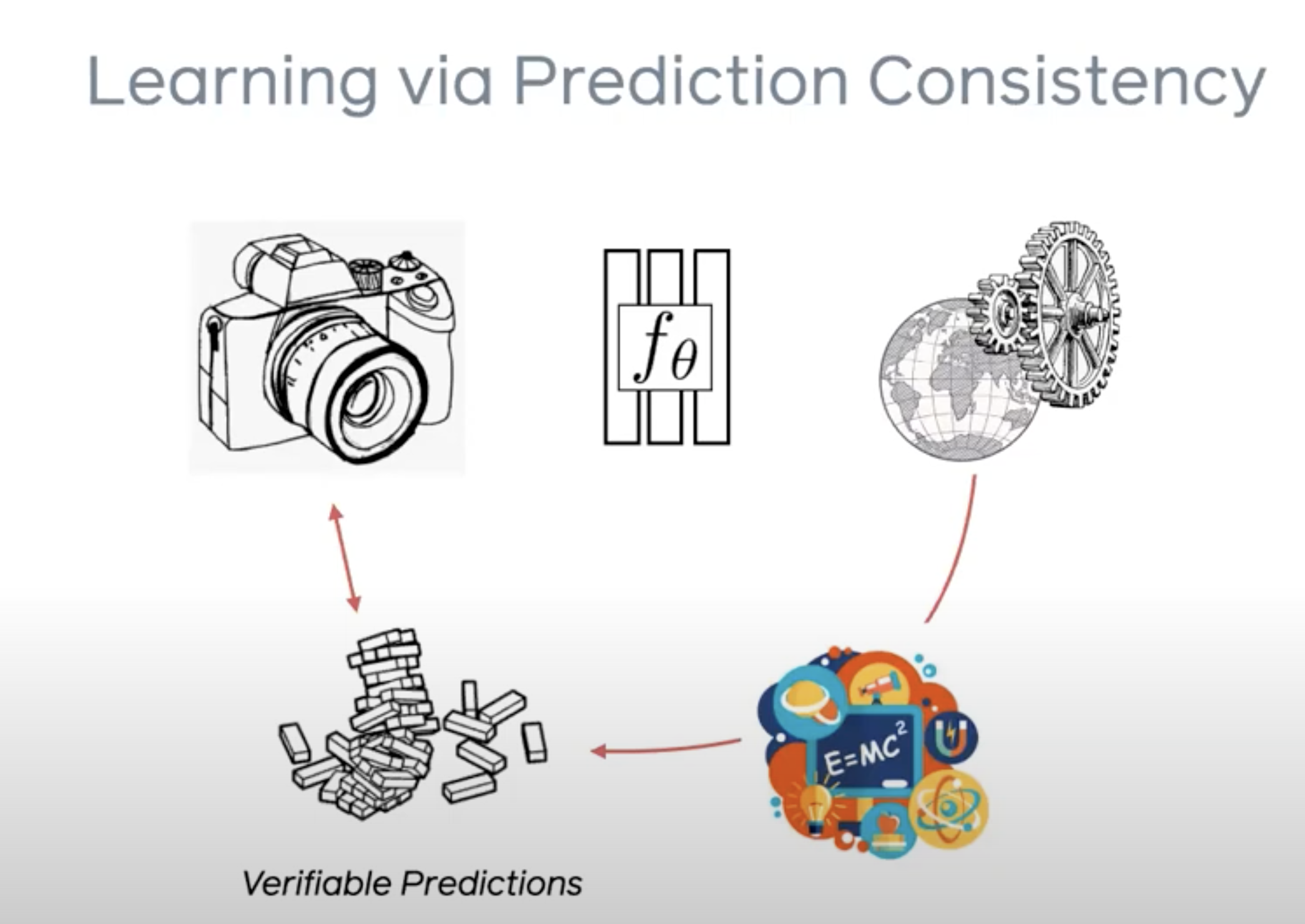
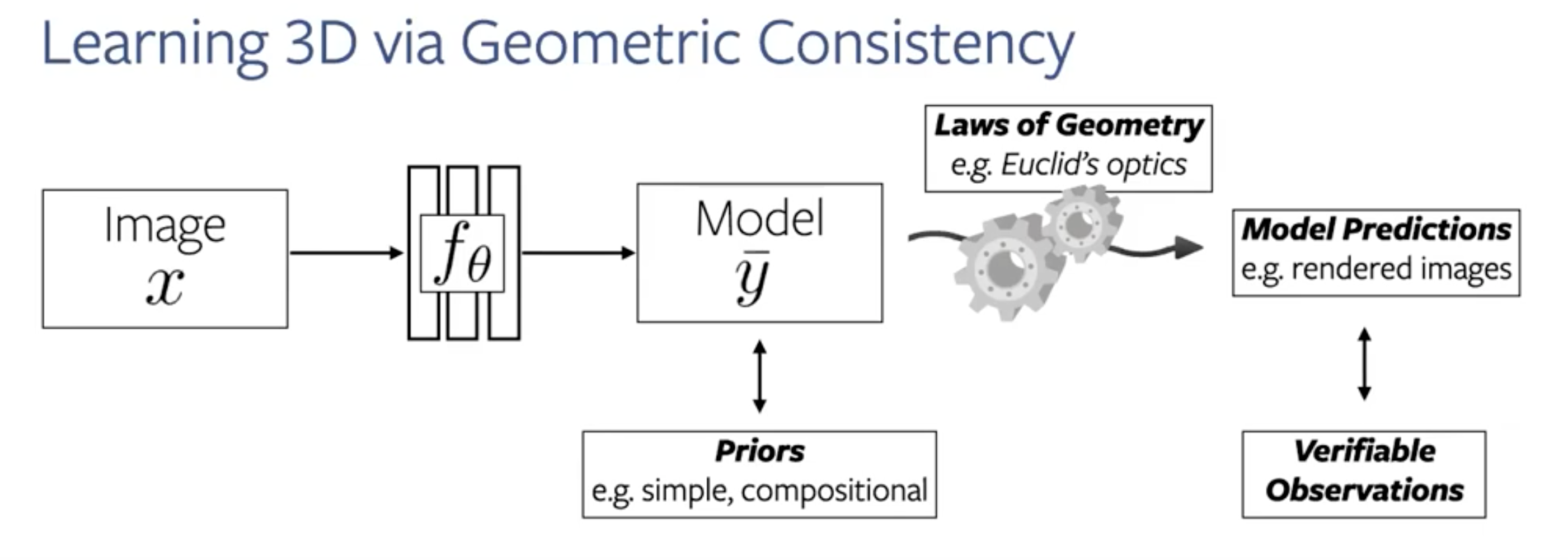
Let me explain via the example of generating 3d models. Here the world model refers to the physical process of converting a 3d object into a 2d image(our eyes do it all the time). More specifically, we build a rendering pipeline which converts the 3d model to the 2d image, making use of our knowledge of the process of rasterization, shading etc. With this ‘prior’, we aim to generate back the input. And calculate the loss. In the process, our model is learning to generate the 3d model from a 2d image.
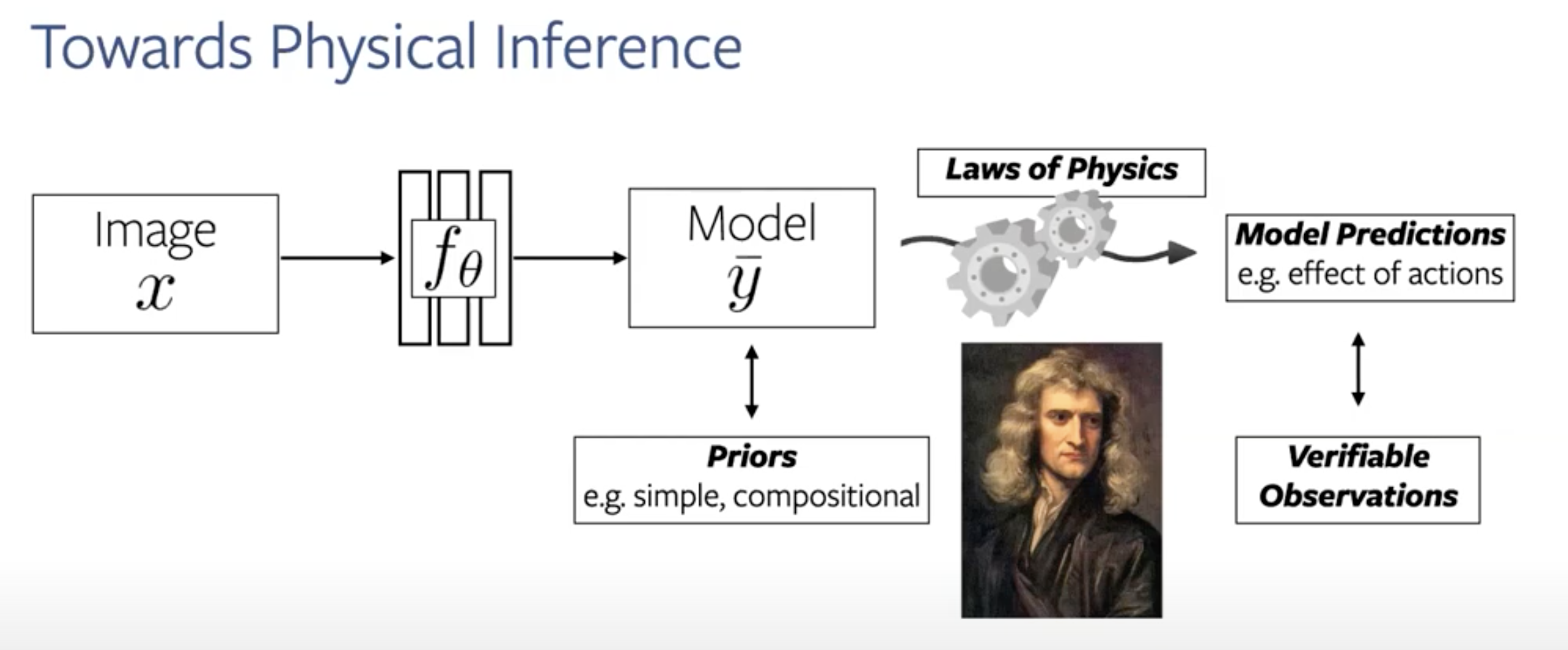
To summarize, this approach expands the scope of deep learning by helping us
- Predicting complex outputs than labels - 3d models, next video frames
- Using only the input as the supervision
Reference: Shubham Tulsiani, FAIR.